


在 2024 年 OCP 全球峰会上,NVIDIA 宣布已将 NVIDIA GB200 NVL72 机架以及计算和交换机托盘液冷设计贡献给开放计算项目 (OCP)。
这篇文章提供了有关此贡献的详细信息,并解释了它如何提高当前设计标准的实用性,以满足现代数据中心对高计算密度的需求。它还探讨了生态系统如何在此基础上构建 GB200 设计,降低了新 AI 数据中心的成本和实施时间。
NVIDIA 的开源计划
NVIDIA 在开源计划方面有着丰富的历史。NVIDIA 的工程师在 GitHub 上发布了超过 900 个软件项目,并已开源了 AI 软件堆栈中的关键组件。例如,NVIDIA Triton 推理服务器现在已集成到所有主要的云服务提供商中,用于在生产环境中服务 AI 模型。此外,NVIDIA 的工程师还积极参与了众多开源基金会和标准组织,包括 Linux 基金会、Python 软件基金会和 PyTorch 基金会。
这种对开放性的承诺延伸到了开放计算项目(OCP),NVIDIA 在这方面持续地为多代硬件产品做出了设计贡献。值得注意的贡献包括 NVIDIA HGX H100 底板,它已成为 AI 服务器的事实上的底板标准,以及 NVIDIA ConnectX-7 适配器,现在它作为 OCP 网络接口卡(NIC)3.0 的基础设计。
NVIDIA 还是 OCP SAI(交换机抽象接口)项目的创始和治理委员会成员,并且是 SONiC(用于云计算的开源网络软件)项目的第二大贡献者。
满足数据中心计算需求
用于训练自回归变换器模型的计算能力需求已经爆炸性增长,在过去五年中增长了惊人的 20,000 倍。今年早些时候发布的 Meta 的 Llama 3.1 405B 模型需要 380 亿 petaflops 的加速计算来进行训练,比一年前发布的 Llama 2 70B 模型增加了 50 倍。训练和服务这些大型模型无法在单个 GPU 上完成;相反,它们必须在庞大的 GPU 集群上进行并行化。
并行化有多种形式——张量并行、流水线并行和专家并行,每一种在吞吐量和用户交互性方面都提供了独特的优势。通常,这些方法会结合使用,以创建最佳的训练和推理部署策略,以满足用户体验要求和数据中心预算目标。要深入了解大型模型的并行技术,请参阅《揭秘兆参数大语言模型的推理部署》。
多 GPU 互联的重要性
在模型并行中,一个常见的挑战是 GPU 间通信的高体量。张量并行 GPU 通信模式凸显了这些 GPU 之间的紧密联系。例如,在 AllReduce 操作中,每个 GPU 必须在神经网络的每一层将计算结果发送到其他所有 GPU,才能确定最终的模型输出。在这些通信过程中,任何延迟都可能导致显著的效率低下,使得 GPU 处于空闲状态,等待通信协议完成。这降低了系统的整体效率,并增加了总拥有成本(TCO)

为了应对这些通信瓶颈,数据中心和云服务提供商利用了 NVIDIA NVSwitch 和 NVLink 互联技术。NVSwitch 和 NVLink 专门设计用于加速 GPU 之间的通信,减少 GPU 空闲时间并提高吞吐量。
在 NVIDIA GB200 NVL72 推出之前,单个 NVLink 域内可连接的 GPU 数量限制在 HGX H200 底板上的八个,每个 GPU 的通信速度为 900 GB/s。GB200 NVL72 设计的引入大大扩展了这些能力:NVLink 域现在可以支持多达 72 个 NVIDIA Blackwell GPU,每个 GPU 的通信速度达到 1.8 TB/s,比最先进的 400 Gbps 以太网标准快了 36 倍。
这种 NVLink 域规模和速度的飞跃可以将兆参数模型(如 GPT-MoE-1.8T)的训练和推理分别加速至 4 倍和 30 倍。


每个 GPU 与其他 GPU 之间的通信速度比最先进的以太网标准快了 36 倍
加速基础设施的创新和贡献
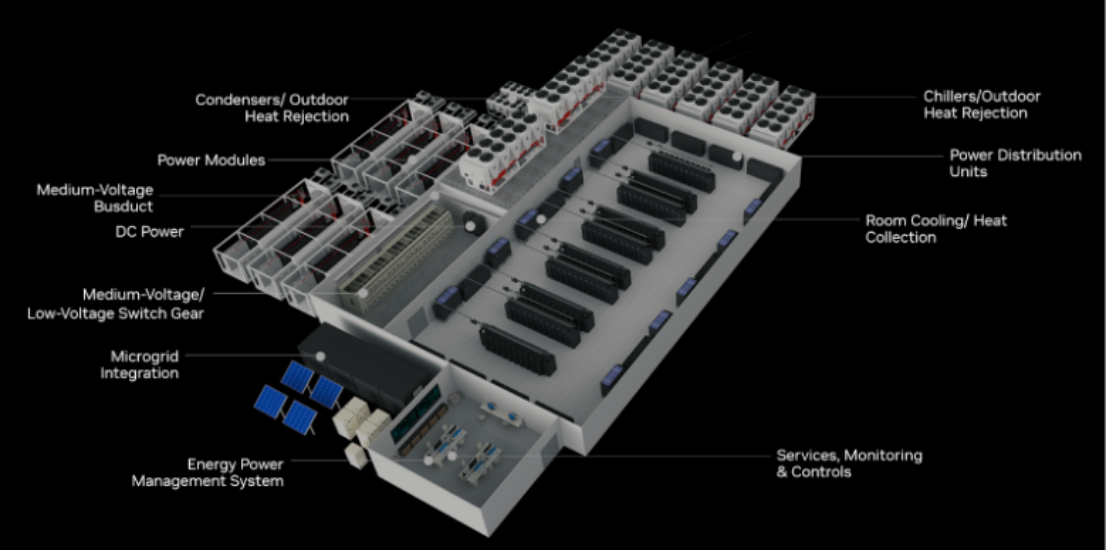
在单个机架内支持如此大型的 GPU NVLink 域的重量、匹配力和冷却需求,需要对机架架构以及容纳 GPU 和 NVSwitch 芯片的计算和交换机机箱进行仔细的电气和机械修改。
NVIDIA 与合作伙伴紧密合作,基于现有的设计原则进行了扩展,以提高它们的实用性并支持 GB200 NVL72 的高计算密度和能效。机架、托盘和内部组件的设计都源自 NVIDIA MGX 架构。如今,我们很高兴开放并与 OCP 分享这些设计,以建立一个模块化且可重用的高计算密度基础设施,用于人工智能领域。

机架加固
为了在一个机架内高效地容纳 18 个计算托盘、9 个交换机托盘和 4 个支持超过 5,000 根铜缆的 NVLink 卡匣,NVIDIA 对现有机架设计实施了几项关键修改,包括:
适应 19” EIA 设备在机架内的 1 RU 形式因素,以增加用于 IO 电缆的空间并提高托盘密度。
增加超过 100 磅的钢结构加固,显著提高了机架的强度和稳定性,以承受其组件和框架之间产生的 6,000 磅的匹配力。
引入后机架扩展,以保护电缆支撑和流量分配装置,确保这些元素的寿命和正常运作。
引入盲插滑轨和锁扣功能,便于 NVLink 的安装、液冷系统的集成,并通过使用盲插连接器简化维护程序。
这种机架重新设计优化了空间利用率,增强了结构完整性,并提高了整体系统的可靠性和可维护性。
大容量总线
为了适应机架的高计算密度和增加的功率要求,增强型高容量总线开发了一种新的设计规范。这种升级的总线与现有的ORV3保持相同的宽度,但具有更深的轮廓,显著提高了其载流量。新设计支持更高的1400安培电流,与当前标准相比,电流增加了2倍。这种增强确保了母线能够有效地处理现代高性能计算环境的高功率需求,而不需要机架内额外的水平空间。
NVLink cartridges
为了实现NVLink域中所有72个NVIDIA Blackwell GPU之间的高速通信,我们采用了一种新颖的设计,在机架后部垂直安装了四个NVLink cartridges。这些盒式磁带可容纳5000多条活动铜缆,提供130 TB/s和260 TB/s的AllReduce带宽,令人印象深刻.
这种设计确保了每个GPU都可以以1.8TB/s的速度与域中的其他GPU通信,从而显著提高了整体系统性能。作为我们提交的一部分,我们提供了有关这些NVLink墨盒的体积和精确安装位置的详细信息,为高性能计算基础设施的未来实施和改进做出了贡献.
液冷集管(Liquid Cooling Manifolds)和浮动盲插(Floating Blind Mates)
为了高效管理机架所需的120KW冷却能力,我们采用了直接液体冷却技术。在现有设计的基础上,我们引入了两项关键创新。首先,我们开发了一种增强型Blind Mate Liquid
其次,我们创建了一种新型的浮动盲板配合托盘连接,它有效地将冷却剂分配到计算和开关托盘,显著提高了液体快速断开装置在机架中对齐和可靠配合的能力。通过利用这些增强的液体冷却解决方案,我们能够满足现代高性能计算环境的高热管理需求,确保机架组件的最佳性能和寿命。
高效的冷却和对各种用户需求的适应性
为了适应机架的高计算密度,我们引入了1RU液冷计算和交换机托盘的外形尺寸。我们还开发了一种新的、更密集的DC-SCM(数据中心安全控制模块)设计,比当前标准小10%。此外,我们还实现了更窄的母线连接器,以最大限度地利用后面板空间。这些修改优化了空间利用率,同时保持了性能。
此外,为计算托盘创建了一个模块化机架设计,可以灵活地适应不同的用户I/O要求。这些增强功能共同支持计算和交换机托盘的1RU液冷外形,显著提高了机架的计算密度和网络能力,同时确保了高效的冷却和对各种用户需求的适应性。
新推出的 NVIDIA GB200 NVL72 参考架构
在 OCP 上,NVIDIA 还与 Vertiv 共同宣布了全新的 GB200 NVL72 参考架构。Vertiv 是一家在电源和冷却技术领域的领导者,并且在设计、构建和服务高计算密度数据中心方面具有专长。这一新的参考架构将显著减少云服务提供商和数据中心部署 NVIDIA Blackwell 平台的实施时间。
这个新的参考架构消除了数据中心需要从头开始开发自己的电源、冷却和空间设计来适应 GB200 NVL72 的需求。通过利用 Vertiv 在空间节省电源管理和高能效冷却技术方面的专长,数据中心可以部署全球 7MW 的 GB200 NVL72 集群,将实施时间减少多达 50%,同时减少电源空间占用并提高冷却能效。
 WeChat
WeChat
 Profile
Profile